Friday, May 1, was International Workers’ Day—a public holiday in many parts of the world, but not the United Stares or New Zealand. But thanks to yet another example of a software fault in a highly complex network of internet infrastructure, a significant proportion of New Zealand workers reliant on the services of One NZ, the country’s number two internet service provider (with around 20 to 24 percent market share) experienced an unexpected workers’ holiday when service went down for between eight and 12 hours. This outage bears remarkable similarities to catastrophic network outages of Optus in Australia and Rogers in Canada and software-related outages of CrowdStrike and Amazon Web Services in recent years.
The One NZ outage drew attention once again to the matter of where responsibility should lie for building resilience to cope with these sorts of outages. The economic consequences of these events live very far removed from the underlying cause. The One NZ fault has been traced to the provision of software to the firm by a third-party vendor.
Quite likely this vendor supplies software to network operators in many different countries—all of whom have slightly different configurations, which potentially lead to slightly different outcomes when the same upgrades are implemented in all locations. These outcomes are nearly impossible to foresee. The same upgrade may work perfectly in a vast number of cases, but where it doesn’t, the consequences are wide-reaching and extremely costly. While the vendor may have a compensation arrangement with the immediately proximate firm (such as One NZ), it does not have such arrangements with the hundreds and thousands (in some cases, millions) of customers affected.
Moreover, the consequences are becoming increasingly more costly as more businesses and individuals utilize telecommunications and internet capabilities as a fundamental part of their operations. And as technical and economic standardization requires the networks themselves to centralize much of their operations remotely in data centers and cloud operations, the scale of the outages increases. Previously, when software controlling a single cellphone tower failed, only that tower went down and losses were geographically contained. But now, the software controls vast numbers of towers—along with all the other packet-related infrastructure the telecommunications network manages—so the scale of the problem grows exponentially.
The One NZ case illustrates the problem. The fault took down all 4G and 5G mobile services across the lower part of the North Island and all the South Island (see Figure 1). It took down services of customers of other networks in rural regions due to the collaboration of the three New Zealand companies in the Rural Connectivity Group in the affected area. It took down the connections of networks (notably 2 degrees) using One NZ towers under roaming agreements in suburban areas. It took out all the internet connections sold by One NZ, not just on its own fixed wireless network but also for its fiber and ADSL/VDSL broadband customers, whose last-mile connections are provided by other firms on their infrastructure but sold by One NZ, because the software fault occurred somewhere in core operations of the system where One NZ manages all digital messaging, not just messages to and from towers and other remote locations such as curbside boxes and interconnection points. Upwards of one million customers were likely affected—one-fifth of the New Zealand population. At least one safety-related service—the Automobile Association, which provides breakdown services and whose mobile response units and offices in most New Zealand towns in the affected areas use One NZ connections—was unable to operate.
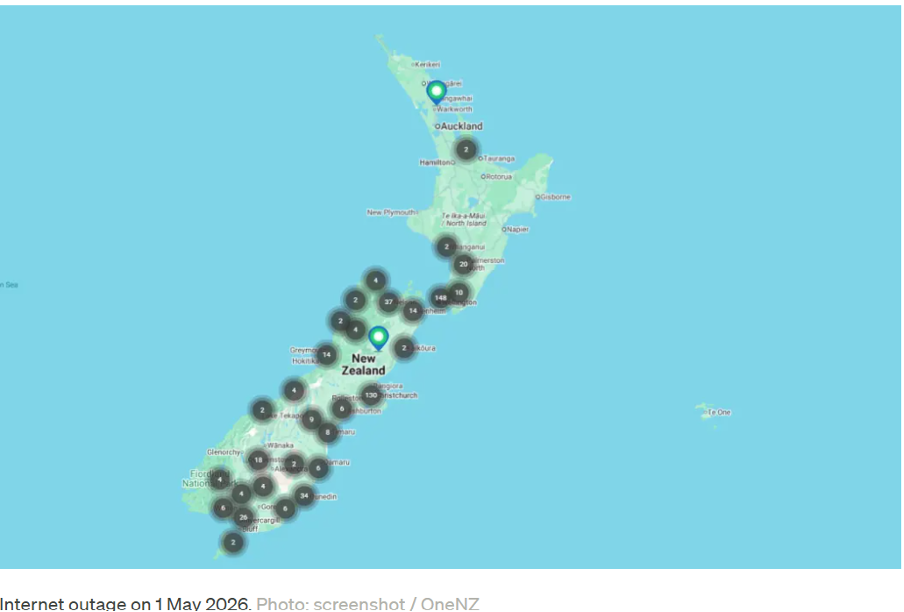
The problem was worse than it might have been also because of social and workplace changes. Since the COVID-19 pandemic, the number of people working from home has increased markedly. This includes call center operators working permanently from remote bases and many others taking advantage of workplace policies supporting remote working for a few days of the week. I am one of those who, because of the outage, lost hours of productivity and incurred appreciable out-of-pocket expenses in petrol and train fares to go to work in their offices when they had planned to work from home on a Friday—the most popular day for such flexible arrangements. But what of the costs to clients of (say) an insurance firm whose agent happened to be a One NZ customer and who couldn’t work on their case that day as planned? Such consequences are manifold—and the costs soon mount up to a nontrivial amount.
The pattern is now abundantly clear. Changes in the workplace and the way communications networks are managed have increased the scale and scope of vulnerabilities to network outages. The social costs are vast and increasing. Addressing both network and commercial resilience is becoming an ever more urgent policy matter.